In higher eukaryotes, many genes are transcribed into mRNA only in specialized cell types. For example, mRNAs encoding globin proteins are found only in erythrocyte precursor cells, called reticulocytes. Likewise, the mRNA encoding albumin, the major protein in serum, is produced only in liver cells where albumin is synthesized. The specific DNA sequences expressed as mRNAs in a particular cell type can be cloned by synthesizing DNA copies of the mRNAs isolated from that type of cell, and then cloning the DNA copies in plasmid or bacteriophage λ vectors.
DNA copies of mRNAs are called complementary DNAs(cDNAs); clones of such DNA copies of mRNAs are called cDNA clones. In addition to representing only the sequences expressed as mRNAs in a particular cell type, cDNA clones lack the noncoding introns present in genomic DNA clones. Thus the amino acid sequence of a protein can be determined directly from the nucleotide sequence of its corresponding cDNA. Many genes in higher eukaryotes are too large to be included in a single λ clone because of their large introns. In contrast, all full-length cDNAs, containing the entire protein-coding sequence, can be included in a single λ clone. However, because of methodological difficulties, not all cDNA clones are full length when initially produced; to obtain a full-length cDNA, it often is necessary to isolate several overlapping cDNA clones and then ligate them at rare restriction sites. Just as a large collection of clones containing fragments of genomic DNA representing the entire genome of a species is called a genomic library, a large collection of cDNA copies of all the mRNAs in a cell type is called a cDNA library.
Isolation of mRNAs and Synthesis of cDNAs
The first step in preparing a cDNA library is to isolate the total mRNA from the cell type or tissue of interest. Nature has greatly simplified the isolation of eukaryotic mRNAs: the 3′ end of nearly all eukaryotic mRNAs consists of a string of 50 – 250 adenylate residues, the poly(A) tail. Because of their poly(A) tail, mRNAs can be easily separated from the much more prevalent rRNAs and tRNAs present in a cell extract by use of a column to which short strings of thymidylate (oligo-dTs) are linked to the matrix. When a cell extract is passed through an oligo-dT column, the mRNA poly(A) tails base-pair with the oligo-dTs, binding the mRNAs to the column. Since rRNAs, tRNAs, and other molecules do not bind to the column, they can be washed away. The bound mRNAs are recovered by elution with a low-salt buffer.

Isolation of eukaryotic mRNA by oligo-dT column affinity chromatography. Isolated cytoplasmic RNA consists mostly of ribosomal RNAs (rRNAs) and transfer RNAs (tRNAs).
The enzyme reverse transcriptase, which is found in retroviruses, is then used to synthesize a strand of DNA complementary to each mRNA molecule. This enzyme can polymerize deoxynucleoside triphosphates into a complementary DNA strand using an RNA molecule as template. Like other DNA polymerases, reverse transcriptase can add nucleo-tides only to the 3′ end of a preexisting primer base-paired to the template. Added free oligo-dT serves this function by hybridizing to the 3′ poly(A) tail of each mRNA template.

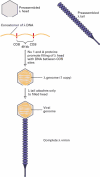
Preparation of a bacteriophage λ cDNA library. A mixture of mRNAs, isolated as shown in Figure is used to produce cDNAs corresponding to all the cellular mRNAs.
Conversion of Single-Stranded cDNA to Double-Stranded cDNA
After cDNA copies of isolated mRNAs are synthesized, the mRNAs are removed by treatment with alkali, which hydrolyzes RNA but not DNA. The single-stranded cDNAs then are converted to double-stranded DNA molecules. To do this, the 3′ end of each cDNA strand is elongated by adding several residues of a single nucleotide (e.g., dG) through the action of terminal transferase, a unique DNA polymerase that does not require a template, but simply adds deoxynucleotides to free 3′ ends. A synthetic oligo-dC primer then is hybridized to this 3′ oligo-dG. DNA polymerase, which uses the oligo-dC as a primer, then is used to synthesize a DNA strand complementary to the original cDNA strand. These reactions produce a complete double-stranded DNA molecule corresponding to each of the mRNA molecules in the original preparation.Each double-stranded DNA, also called cDNA, contains an oligo-dC – oligo-dG double-stranded region at one end and an oligo-dT – oligo-dA double-stranded region at the other end.
Addition of Linkers and Incorporation of cDNA into a Vector
To prepare double-stranded cDNAs for cloning, short restriction-site linkers first are ligated to both ends. These are double-stranded DNA segments, usually ≈10 – 12 bp long, that contain the recognition site for a particular restriction enzyme. Restriction-site linkers are prepared by hybridizing chemically synthesized complementary oligonucleotides. The ligation reaction is carried out by DNA ligase from bacteriophage T4, which can join “blunt-ended” double-stranded DNA molecules lacking sticky ends. Although blunt-end ligation is relatively inefficient, the ligation reaction can be driven to completion by using high concentrations of linkers.
The resulting double-stranded cDNAs, which contain a restriction-site linker at each end, are treated with the restriction enzyme specific for the linker; this generates cDNA molecules with sticky ends at each end. To prevent digestion of any cDNAs that by chance have a recognition sequence for this restriction enzyme within the cDNA sequence, the mixture of double-stranded cDNAs is treated with the appropriate modification enzyme before addition of the linkers. This enzyme methylates specific bases within the restriction-site sequence, preventing the restriction enzyme from digesting the methylated sites.
The final step in construction of a cDNA library is ligation of the restriction-cleaved double-stranded cDNAs, which now have sticky ends, to plasmid or λ phage vectors that have been cut to generate complementary sticky ends. The recombinant vectors then are plated on a lawn of E. coli cells, producing a library of plasmid or λ clones.Each clone carries a cDNA derived from a single mRNA.